들어가며
AI분야에서 생성모델에 대한 연구가 활발해지고 있습니다. 이제는 많이들 사용하고 계실 OpenAI의 chatGPT부터 원하는 이미지를 만들고 편집할 수 있는 Stable Diffusion까지 연구 뿐만 아니라 실제 산업이나 응용 측면에서도 생성모델이 활용되고 있습니다. 저 또한 Diffusion을 활용한 연구를 하는데, 이를 위해 생성모델의 기초부터 다시 공부하면서 겸사겸사 그 내용을 정리해 공유하려 합니다. 생성모델이 무엇인지, 그 종류에는 무엇이 있는지, 그리고 가장 흔하게 쓰이는 구조인 GAN과 VAE까지 살펴보도록 하겠습니다.
1. Discriminative model vs Generative model
1.1 Discriminative model
판별모델(Discriminative model)은 데이터 x가 주어졌을 때 label Y가 나타날 조건부확률 $p(Y|X)$를 예측하는 모델을 의미하며, 분류모델이라고도 불립니다. label Y가 사용되기 때문에 지도학습(Supervised Learning)입니다.
1.2 Generative model
생성모델(Generative model)을 한마디로 정리하면, input x가 주어졌을 때 p(x)라는 데이터 분포(distribution)를 추정하는 모델입니다. 생성모델의 학습에는 label Y를 사용하는 지도학습(Supervised learning) 방법과, 사용하지 않는 비지도학습(Unsupervised learning)이 모두 가능합니다.
1.2.1 Supervised leanring
지도학습은 Y가 있기 때문에 아래 그림과 같이 각 클래스 별 데이터의 확률 분포인 P(X|Y)와 P(Y)를 추정한 다음 베이즈 정리(Bayes' theorem)를 이용해 $p(Y|X)$를 구하는 방법입니다.

1.2.2 Unsupervised learning
비지도학습은 Y 없이, input x 의 분포 자체를 추정하는 것을 의미합니다. 이러한 input x의 분포를 추정하는 딥러닝 방식에는 Explicit density와 Implicit density가 존재합니다. Explicit은 input x를 '보고' 확률분포를 추정하는 방법이고, Implicit은 x를 '보지 않고' 간접적으로 확률분포를 추정하는 방법입니다. 아래 figure에 이 두가지 추정방식에 대해 여러 갈래의 방법들이 추가로 적혀있는데 이 중에 주목할만한 모델이 바로 Explicit의 대표 주자인 VAE(Variational Autoencoder)와 Implicit의 대표주자인 GAN입니다. 모델과 함께 explicit과 implicit의 추정 방법에 대해 자세히 살펴보겠습니다.

Explicit density : VAE(Variational Autoencoder)
VAE에 대해서는 이야기 할 거리가 많아 자세한 설명은 다른 글에서 다루겠습니다. 간단히 설명하면 VAE는 input x가 인코더를 거쳐 저차원의 latent vector가 되고, 이 압축된 latent vector가 다시 디코더를 거쳐 원래 데이터로 복원되는 인코더-디코더 구조입니다. 이 때 input x와 복원된 x'가 최대한 비슷해질 수 있도록 reconstruction loss가 적용됩니다. 따라서 이 인코더, 디코더를 학습하는데 input x 분포에 대한 정보가 필요하므로 Explicit 한 학습방법이라고 할 수 있습니다.

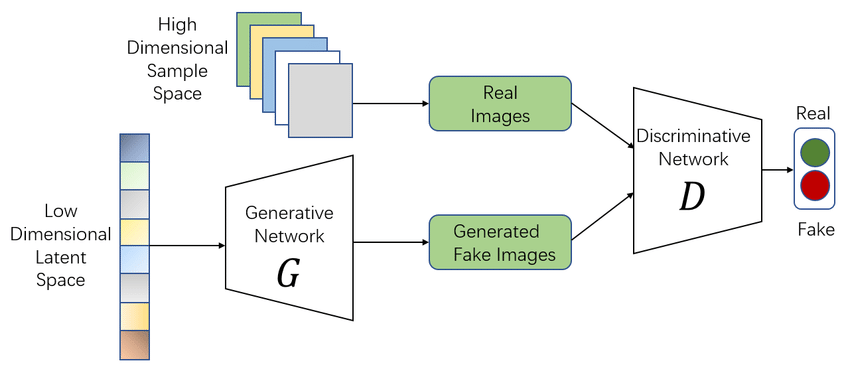
Implicit Density : GAN
반대로 GAN은 Implicit한 방법으로, input x의 분포를 모르는 상태로 모델이 학습됩니다. 이는 GAN의 독특한 구조때문입니다. GAN은 생성기(Generator)와 판별기(Discriminator)로 이루어져 있고, 이 두 모듈이 한번씩 번갈아가면서 학습되는 방식입니다. 생성기가 데이터를 만들어내면, 판별기가 그 데이터가 진짜(원래 input x)인지 가짜(생성기가 만들어낸 데이터)인지 구분하여 그 결과를 생성기에 피드백해줍니다. 생성기는 최대한 input 데이터와 유사한 데이터를 만들어 판별기를 속일 수 있도록 학습됩니다. 따라서 생성기는 input x의 분포를 가이드로 학습되는 것이 아니라, 오로지 판별기의 판별 결과에만 의존하여 학습되는 것이기 때문에 간접적인 정보만을 이용한다고 볼 수 있습니다. 이러한 관점에서 Implicit한 방법이라고 할 수 있는 것입니다.